Home / Riconoscere immagini IA
Verifica se un'immagine è creata o manipolata con l'IA
Analisi forense multi-metodo: Vision Transformer, 8 test forensi, CLIP, fingerprinting del generatore (Midjourney, DALL-E, Stable Diffusion, Flux), watermark (C2PA, SynthID) e decisione ensemble con rejection option.
Analizza la tua immagine per verificare se è creata con AI
Carica un'immagine per scoprire se è stata manipolata o generata con intelligenza artificiale. Il sistema analizzerà oltre 30 parametri tecnici inclusi CLIP, Fingerprinting del generatore, Watermark Detection e fornirà una decisione ensemble combinando tutti i metodi.
Come funziona il riconoscimento di immagini generate o manipolate con l'IA
Questo sistema utilizza tecniche di intelligenza artificiale forense di ultima generazione per identificare se un'immagine è stata manipolata o generata completamente da IA. L'analisi combina algoritmi di machine learning con tecniche di elaborazione del segnale per rilevare pattern invisibili all'occhio umano. Novità 2026: Analisi semantica CLIP, identificazione del generatore AI (Midjourney, DALL-E, Stable Diffusion, Flux), rilevamento watermark AI (C2PA, SynthID), e decisione ensemble multi-metodo. Prova subito il sistema →
Tecniche di analisi utilizzate per riconoscere immagini false
Vision Transformer Multi-Modale (ViT-B/16 + EXIF)
Il sistema principale utilizza un Vision Transformer (ViT-B/16) combinato con un encoder EXIF multi-layer perceptron. Il modello analizza simultaneamente le features visive estratte dal ViT e 17 features EXIF (metadati fotocamera, varianza laplaciana, densità bordi, entropia colore, artefatti di compressione). Questa architettura multi-modale raggiunge accuratezza >95% nella classificazione Real vs AI-Generated.
Analisi del Rumore Residuo (NLM Denoising)
Utilizziamo l'algoritmo Non-Local Means Denoising per estrarre il pattern di rumore residuo. Le immagini generate da IA presentano una varianza del rumore anomala (tipicamente < 3.0) rispetto alle fotografie autentiche. L'analisi viene effettuata su blocchi di 64x64 pixel per identificare inconsistenze locali.
Trasformata di Fourier FFT GAN-specific
⚠️ GAN-specific (Frank et al. ICML 2020): rileva artefatti periodici da transposed convolution tipici delle GAN. NON affidabile per modelli Diffusion e Autoregressivi (Gemini, GPT-4o, Midjourney). Applichiamo la Fast Fourier Transform per analizzare lo spettro di frequenza: le GAN mostrano pattern periodici con periodic_score > 0.03 e frequency_ratio tra 0.74-0.79.
Coerenza Locale dei Gradienti
Calcoliamo la coerenza locale dei gradienti su patch 16x16 per analizzare la distribuzione delle direzioni dei bordi. Le immagini IA mostrano pattern di coerenza innaturalmente uniformi rispetto alle fotografie reali. Il sistema visualizza la mappa di coerenza per identificare regioni sintetiche.
Pattern Colore (CFA/Bayer)
Convertiamo l'immagine in spazio colore LAB per analizzare la distribuzione cromatica. Le fotocamere reali applicano un filtro CFA (Bayer) che introduce correlazioni specifiche tra i canali colore — assenti nelle immagini AI. Il sistema analizza entropia, deviazione standard e rapporti tra canali per rilevare l'assenza di questa firma naturale. Basato su CVPR 2025 "Secret Lies in Color".
Decomposizione Wavelet (PyWavelets db4)
Applichiamo la trasformata wavelet discreta (DWT) con base Daubechies-4 su 4 livelli. Le immagini IA mostrano una curtosi dei coefficienti di dettaglio > 5, molto superiore alle immagini naturali. Il sistema decompone l'immagine in coefficienti di approssimazione (cA) e dettaglio (cH, cV, cD). La base db4 è validata in letteratura per il rilevamento GAN (Franzen et al., IEEE 2022).
Artefatti Spettrali DCT
Analisi degli artefatti DCT (Discrete Cosine Transform) su scala di frequenza multipla. Le immagini AI generative mostrano un eccesso di energia alle frequenze Nyquist — caratteristico del processo di upsampling interno. Il sistema calcola lo spectral score su 3 scale e confronta il profilo spettrale con quello atteso da immagini naturali. Basato su CVPR 2025 "Any-Resolution AI-Generated Image Detection by Spectral Learning".
Statistiche Pixel (Istogramma e Correlazioni RGB)
Analisi dell'istogramma di luminosità, correlazioni tra canali RGB e varianza locale. Le immagini AI presentano istogrammi più regolari (assenza del rumore di quantizzazione da sensore), correlazioni RGB troppo uniformi e variance dei blocchi locali ridotta. Il sistema calcola histogram_roughness, channel_correlations e block_variance_cv per rilevare pattern sintetici.
NPR — Upsampling Residual Analysis AR Models
Analisi dei residui di upsampling ispirati al NPR (Nearest Pixel Relationship, CVPR 2024). Questo approccio utilizza 4 kernel differenziali direzionali e analisi FFT-based del Nyquist ratio per rilevare le tracce lasciate dal decoder dei modelli autoregressivi (Gemini Imagen, GPT-4o). È il test più sensibile per modelli AR che sfuggono ai test tradizionali.
CLIP Semantic Analysis
Utilizziamo OpenAI CLIP (ViT-Base/32) per analizzare la similarità semantica dell'immagine con 18 prompt AI vs Real. Il modello confronta l'embedding visivo con descrizioni come "an AI generated image", "a synthetic image", "an image created by Midjourney" vs "a real photograph", "an authentic photo". Il sistema calcola uno score AI likelihood basato sulla similarità semantica.
Generator Fingerprinting
Identifica il generatore AI specifico basandosi su profili caratteristici di Midjourney (alta saturazione, stile artistico), Stable Diffusion (noise pattern, color bleeding), DALL-E (alta coerenza, bordi puliti) e Flux (texture realistiche, alto dettaglio). Analizza saturazione, contrasto, smoothness, edge quality e color coherence.
Watermark & Provenance Detection
Ricerca marcatori di provenienza AI: C2PA/Content Credentials (standard aperto CAI — supportato da Adobe, Google, Microsoft, OpenAI, Midjourney e molti altri), SynthID (watermark invisibile pixel-level di Google DeepMind), analisi steganografica LSB per pattern nei bit meno significativi, e scansione dei metadati EXIF/XMP per rilevare tool AI.
Ensemble Decision con Rejection Option
Combina tutti i metodi di analisi con pesi ottimizzati: ViT Model (30%), 8 Test Forensi (25%), CLIP (20%), Fingerprint (10%), Watermark (5% — boost dinamico al 15% in presenza di C2PA). Include rejection option: se la confidenza è < 40% o l'accordo tra metodi < 50%, il sistema indica "INCERTO". Output su 5 livelli: REALE, PROBABILMENTE REALE, INCERTO, PROBABILMENTE AI, GENERATA DA AI.
Indicatori chiave per riconoscere immagini generate da IA
- Metadati EXIF mancanti o incongruenti: Assenza di informazioni sulla fotocamera (Make, Model, Lens), mancanza di parametri di esposizione (ISO, aperture, shutter speed), software di generazione AI nei metadati
- Uniformità anomala del rumore: Varianza del rumore < 3.0 calcolata su blocchi 64x64px, rumore sintetico statisticamente diverso da quello dei sensori fotografici reali
- Pattern periodici nelle frequenze FFT (GAN-specific): Periodic score > 0.03, frequency_ratio tra 0.74-0.79, artefatti regolari da transposed convolution GAN. Non rilevante per modelli Diffusion e AR.
- Coerenza locale dei gradienti: Pattern di direzioni dei bordi troppo uniformi su scala locale, tipico delle immagini sintetiche
- Distribuzione colore anomala (assenza firma CFA): Mancanza delle correlazioni inter-canale tipiche del filtro Bayer delle fotocamere reali, distribuzione a*b* troppo uniforme
- Decomposizione wavelet anomala: Curtosi coefficienti dettaglio > 5, pattern di decadimento energetico tipico della sintesi AI su 4 livelli wavelet db4
- Artefatti spettrali DCT: Eccesso di energia alle frequenze Nyquist su scale multiple, caratteristico del processo di upsampling dei modelli generativi
- Statistiche pixel anomale: Istogramma troppo regolare (assenza rumore quantizzazione), correlazioni RGB uniformi, block variance CV ridotto
- Residui upsampling NPR: Kernel differenziali direzionali e Nyquist ratio anomalo, indicativi delle operazioni di upsampling nei decoder dei modelli autoregressivi (Gemini, GPT-4o)
- CLIP Semantic Similarity: Score AI > 60% indica alta similarità con concetti come "AI generated image", "synthetic image", "created by Midjourney/DALL-E"
- Generator Fingerprint Match: Pattern caratteristici di Midjourney, Stable Diffusion, DALL-E, Flux identificati tramite analisi statistica multi-feature
- Manifest C2PA rilevato: Presenza di C2PA Content Credentials (standard CAI — Adobe, Google, Microsoft, OpenAI, Midjourney), watermark SynthID di Google DeepMind, o tool AI nei metadati EXIF/XMP
- Disaccordo tra metodi di analisi: Se l'accordo tra i vari metodi è < 50%, il risultato è considerato INCERTO e richiede revisione esperta
Il sistema integra un Vision Transformer multi-modale che analizza simultaneamente features visive (estratte dal ViT-B/16) e features EXIF/image analysis. Novità 2026: I risultati vengono combinati con analisi CLIP, fingerprinting del generatore e rilevamento watermark in un ensemble multi-metodo con rejection option e boost dinamico C2PA per massimizzare l'affidabilità.
Accuratezza del sistema 2026
Il sistema raggiunge un'accuratezza del:
- ✓ 95%+ per immagini generate da AI
- ✓ 90% per manipolazioni significative
- ✓ 85% per editing standard
Metodi combinati:
- • Vision Transformer (50k immagini)
- • 8 Test Forensi Validati
- • CLIP Semantic Analysis
- • Generator Fingerprinting
- • Watermark Detection (C2PA/SynthID)
- • Ensemble con Rejection Option
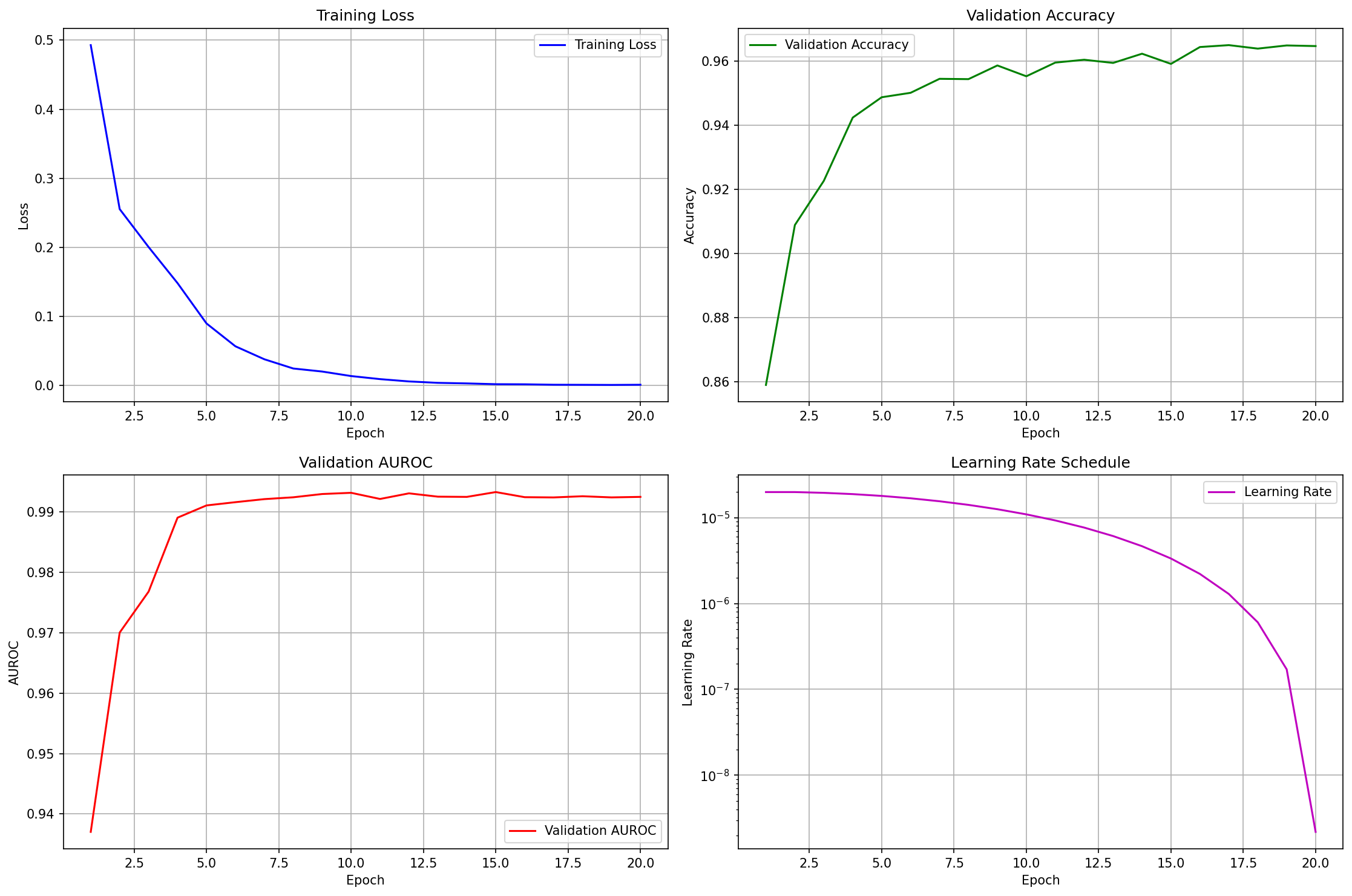
Grafico training (clicca per ingrandire)
Disclaimer Legale
ESCLUSIONE DI RESPONSABILITÀ: Il sistema di analisi fornito è uno strumento di supporto tecnico che non garantisce risultati infallibili. I risultati dell'analisi sono forniti "così come sono" (as-is) senza garanzie di alcun tipo, espresse o implicite. L'utente riconosce che possono verificarsi falsi positivi o falsi negativi e che nessuna tecnologia attuale può determinare con certezza assoluta l'origine o l'autenticità di un'immagine digitale. acquisizioniforensi.it, il suo proprietario, dipendenti e collaboratori declinano ogni responsabilità per qualsiasi danno diretto, indiretto, incidentale, consequenziale o punitivo derivante dall'uso o dall'impossibilità di utilizzo del servizio, inclusi ma non limitati a: (i) errori nella classificazione delle immagini; (ii) decisioni prese sulla base dei risultati dell'analisi; (iii) danni reputazionali o economici derivanti da valutazioni errate; (iv) perdita di dati o interruzioni del servizio. L'utilizzo del sistema implica l'accettazione integrale di questi termini e la rinuncia a qualsiasi pretesa risarcitoria. Per decisioni critiche si raccomanda sempre la consultazione di un esperto forense qualificato.