Questa pagina contiene la documentazione tecnica completa di SeizeDB v1.0.0 — il tool per l'acquisizione forense di database in produzione. Trovi qui il dettaglio del processo di acquisizione, il formato dei file prodotti, l'algoritmo di hashing, le procedure di verifica e la conformità normativa.
Requisiti di sistema
| Piattaforma | Linux x86_64 o ARM64 (binario statico, zero dipendenze) |
| Database | MySQL 5.7+, PostgreSQL 12+, MariaDB 10.5+ |
| Tool di dump | mysqldump (MySQL/MariaDB) o pg_dump (PostgreSQL) — deve essere nel PATH |
| diff | Comando Unix diff — presente su tutte le distribuzioni Linux |
| Rete | HTTPS in uscita verso acquisizioniforensi.it (escrow) e freetsa.org (marca temporale) |
| Spazio disco | ~3x la dimensione del database non compresso |
SeizeDB è un binario statico compilato in Go. Non ha dipendenze runtime — copialo su qualsiasi server Linux ed eseguilo. Nessuna installazione, nessun package manager, nessuna libreria da installare.
Configurazione
SeizeDB legge un file di configurazione JSON:
{
"dbtype": "mysql",
"host": "127.0.0.1",
"port": 3306,
"database": "nome_database",
"username": "utente_ro",
"password": "password_sicura",
"operator_name": "Mario Rossi",
"case_number": "PROC-2026-001",
"apikey": "la_tua_api_key",
"language": "it",
"tsa": "freetsa"
}Sicurezza: imposta i permessi del file con chmod 600 config.json per proteggere le credenziali. La password non viene mai passata come argomento CLI (sarebbe visibile in ps aux).
Interfaccia a riga di comando
# Acquisizione completa
sudo ./SeizeDB-linux-amd64 --config db.json
# Stima senza acquisire (dry-run)
sudo ./SeizeDB-linux-amd64 --config db.json --dry-run
# Sblocco di un'acquisizione cifrata
./SeizeDB-linux-amd64 --unlock UUID --apikey KEY
# Lista acquisizioni in attesa di sblocco
./SeizeDB-linux-amd64 --list-pending| Flag | Descrizione |
|---|---|
--config FILE | Path al file di configurazione JSON (obbligatorio) |
--apikey KEY | Chiave API (o nel campo "apikey" del config) |
--output DIR | Directory di output |
--notroot | Modalità non privilegiata: salta le operazioni che richiedono root |
--verbose | Log dettagliato su stdout |
--tsa PROVIDER | freetsa (default) o infocert (+2 slot) |
--yes | Conferma automatica dello sblocco |
--dry-run | Stima slot senza acquisire |
--unlock UUID | Sblocca un'acquisizione cifrata |
--list-pending | Mostra le acquisizioni cifrate in attesa |
Il processo di acquisizione in 8 step
Step 0 — Preflight Check
Valida la configurazione, testa la connettività al database, verifica la disponibilità del binario di dump, controlla la sincronizzazione dell'orologio tramite NTP (pool.ntp.org), e determina se l'esecuzione è in modalità root o non-root.
Step 1 — Primo Dump
Esegue mysqldump --single-transaction (MySQL/MariaDB InnoDB) o pg_dump --serializable-deferrable (PostgreSQL) per produrre uno snapshot consistente. Il database resta in esecuzione durante l'intero processo. L'hash SHA-256 viene calcolato sul SQL non compresso prima della compressione gzip. Il file non compresso viene poi eliminato.
Step 2 — Hashing per Tabella
Per ogni tabella: estrae il DDL (CREATE TABLE), poi interroga tutte le righe ordinate per chiave primaria. Ogni riga viene serializzata come oggetto JSON con chiavi ordinate deterministicamente e hashata individualmente con SHA-256. Output: file JSONL con campi _row_hash, _pk, _table.
Step 3 — Secondo Dump
Dump identico ripetuto dopo il completamento dell'hashing. Serve per verificare che il database non sia stato modificato durante l'acquisizione.
Step 4 — Verifica Differenze
Decomprime entrambi i dump in file temporanei, rimuove i metadati dei tool di dump (timestamp di completamento, token di sessione PostgreSQL), poi esegue diff. Se il database ha ricevuto scritture durante l'acquisizione, le differenze vengono documentate in un report leggibile.
Step 5 — Fotografia del Sistema
Raccoglie 40+ file di contesto: hostname, OS, CPU, RAM, disco, interfacce di rete, routing, DNS, regole firewall, porte aperte con nomi processo, servizi attivi, moduli kernel, configurazione DB, variabili DB, login utenti, reverse DNS, certificati SSL. In modalità root raccoglie anche lsof del processo DB e /proc/PID/environ.
Step 6 — Generazione Report
Genera: report PDF (con logo), report TXT, report HTML, Data Explorer interattivo (tutti i dati navigabili offline), Mappa Relazioni (grafo vis.js), pagina Sistema, pagina Differenze, pagina Log, pagina Panoramica con glossario.
Step 7 — Marca Temporale e Compressione
Richiede la marca temporale RFC 3161 da FreeTSA (o InfoCert), crea lo ZIP contenente tutti i file, verifica l'integrità dello ZIP tramite doppio hash.
Step 8 — Cifratura
Chiama il server escrow per ottenere una chiave AES-256-CBC, cifra lo ZIP, elimina tutti i dati in chiaro. L'utente non accede mai ai dati non cifrati fino allo sblocco (con addebito slot).
Struttura dei file prodotti
{UUID}.zip
├── manifest.json
├── chain-of-custody.txt
├── operations-log.txt
├── report.pdf / report.txt / report.html
├── index.html / data-explorer.html / system-info.html
├── diff-report.html / operations-log.html
├── timestamp.tsr
├── dump/
│ ├── dump-01-{TS}.sql.gz + dump-01.sha256 + dump-01.gz.sha256
│ ├── dump-02-{TS}.sql.gz + dump-02.sha256 + dump-02.gz.sha256
│ ├── diff-report.txt + diff.patch.gz + diff.sha256
│ └── diff-stats.txt
├── tables/
│ └── {nome_tabella}/
│ ├── structure.sql + structure.sha256
│ └── rows.jsonl + rows.sha256
├── relations/
│ ├── schema.json + schema.dot
│ └── database-map.html
└── system/
└── (40+ file di contesto)Algoritmo di hashing per riga
- Query:
SELECT * FROM tabella ORDER BY chiave_primaria - Per ogni riga, crea una mappa chiave-valore con i nomi delle colonne
- Ordina le chiavi alfabeticamente (ordinamento deterministico)
- Serializza in JSON:
[{"k":"col1","v":"val1"},{"k":"col2","v":42}] - Calcola:
SHA-256(json_bytes) - Salva come
_row_hash: "sha256:abcdef..."nel file JSONL
Gestione tipi speciali:
| DATE/DATETIME/TIMESTAMP | UTC RFC3339 (2026-04-09T14:55:37Z) |
| BINARY/BLOB | Prefisso hex: + codifica esadecimale |
| DECIMAL/NUMERIC | Stringa ("123.456") |
| NULL | JSON null |
| JSON/JSONB | Stringa JSON grezza |
Doppio dump e verifica differenze
- Dump identici (diff vuoto): il database non ha ricevuto scritture durante l'acquisizione. È la condizione ideale.
- Diff non vuoto: normale per database in produzione. Le differenze vengono documentate e spiegate come attività operativa. I metadati dei tool di dump vengono esclusi dal confronto per evitare falsi positivi.
Sincronizzazione orologio NTP
SeizeDB interroga pool.ntp.org prima e dopo l'acquisizione, registrando: offset dell'orologio (millisecondi), stratum NTP (1 = connesso direttamente al clock di riferimento), round-trip time. Questo documenta che tutti i timestamp nell'acquisizione sono accurati entro l'offset misurato.
Marca temporale RFC 3161
Il file timestamp.tsr è un token RFC 3161 emesso da un'autorità di certificazione terza. Prova crittograficamente che il pacchetto esisteva in quella forma a quella data e ora. Provider supportati:
- FreeTSA (default, gratuito)
- InfoCert (qualificata eIDAS, +2 slot)
Sistema di cifratura ed escrow
- Riserva: SeizeDB chiama il server escrow che genera una chiave AES-256-CBC + IV
- Cifratura: lo ZIP viene cifrato localmente con la chiave ricevuta. Il file in chiaro viene eliminato immediatamente.
- Sblocco: l'utente richiede lo sblocco → il server verifica il saldo slot → restituisce la chiave → decifratura locale → scalatura slot → conferma via email/PEC
L'utente non accede mai ai dati in chiaro senza aver pagato.
Report HTML interattivi
Tutte le pagine HTML funzionano offline da file:// — Bootstrap, vis.js e le icone sono integrati nel binario. Nessun CDN, nessun internet richiesto per consultare i report.
| index.html | Panoramica con statistiche, glossario, guida alla lettura |
| report.html | Report forense completo corrispondente al PDF/TXT |
| data-explorer.html | Esplorazione dati con ricerca, filtri, ordinamento, navigazione FK, export CSV |
| database-map.html | Grafo interattivo vis.js delle relazioni tra tabelle |
| system-info.html | Snapshot completo del sistema con JSON syntax-highlighted |
| diff-report.html | Diff colorato con statistiche |
| operations-log.html | Log cronologico con timestamp al millisecondo e ricerca |
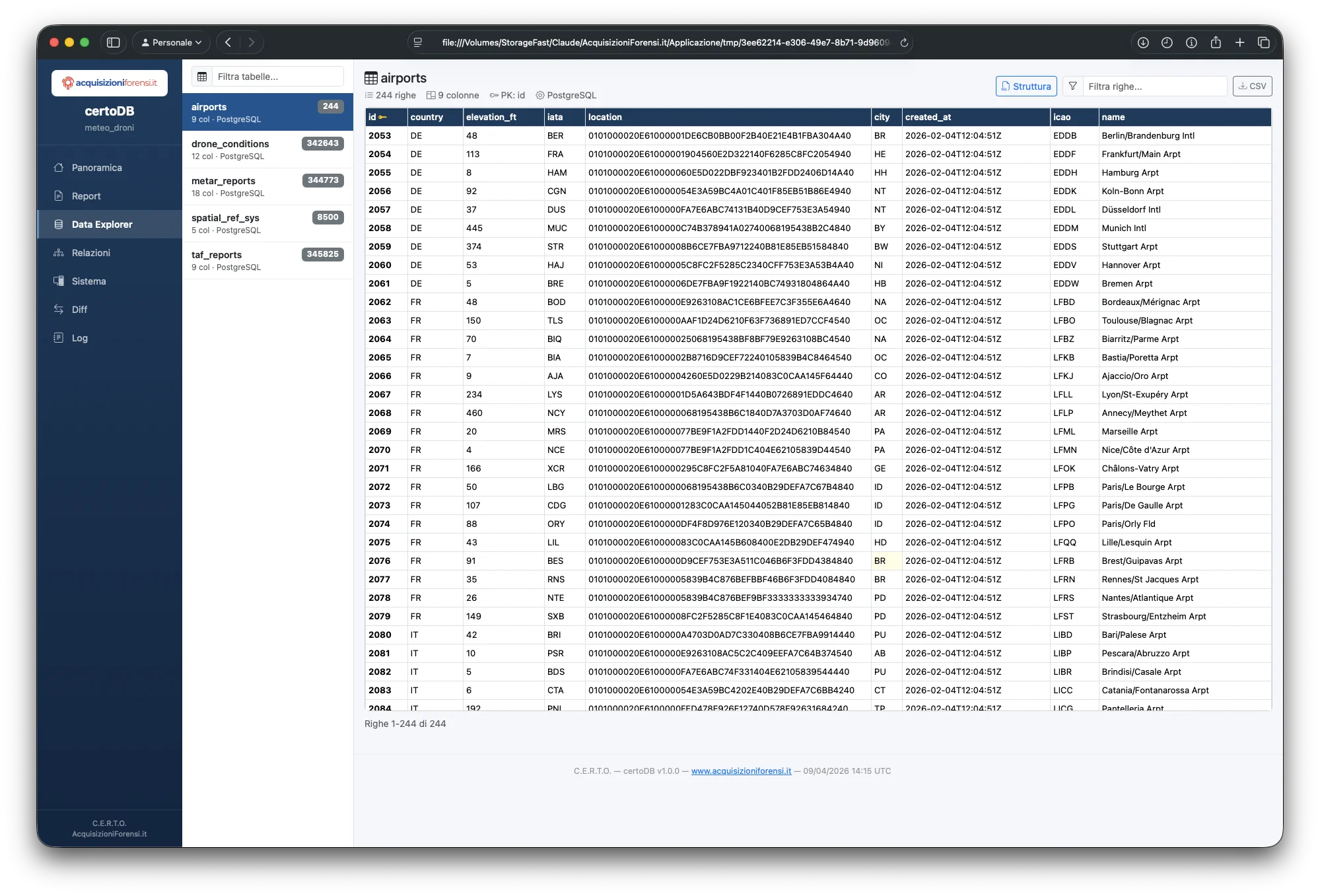
Data Explorer
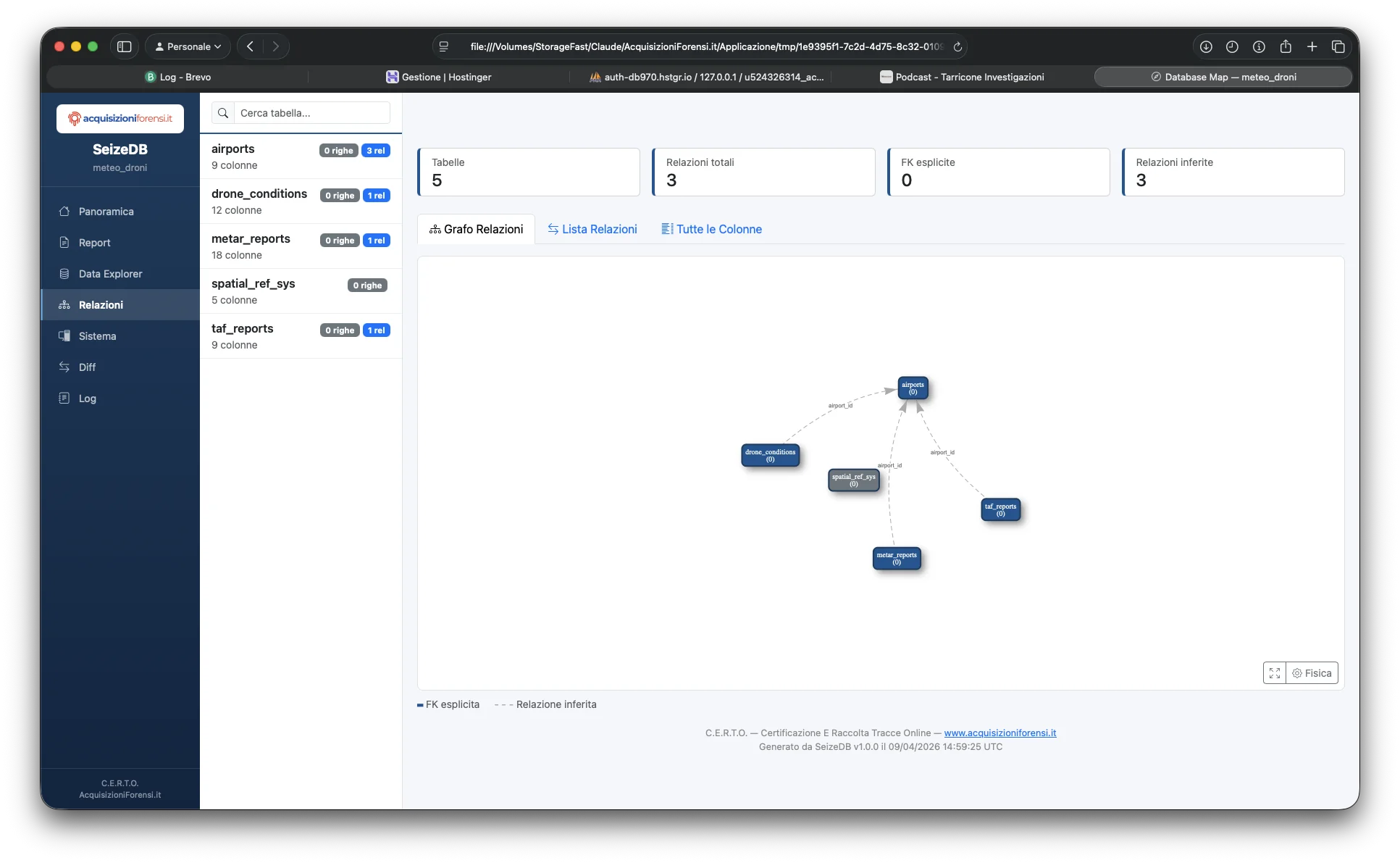
Mappa Relazioni
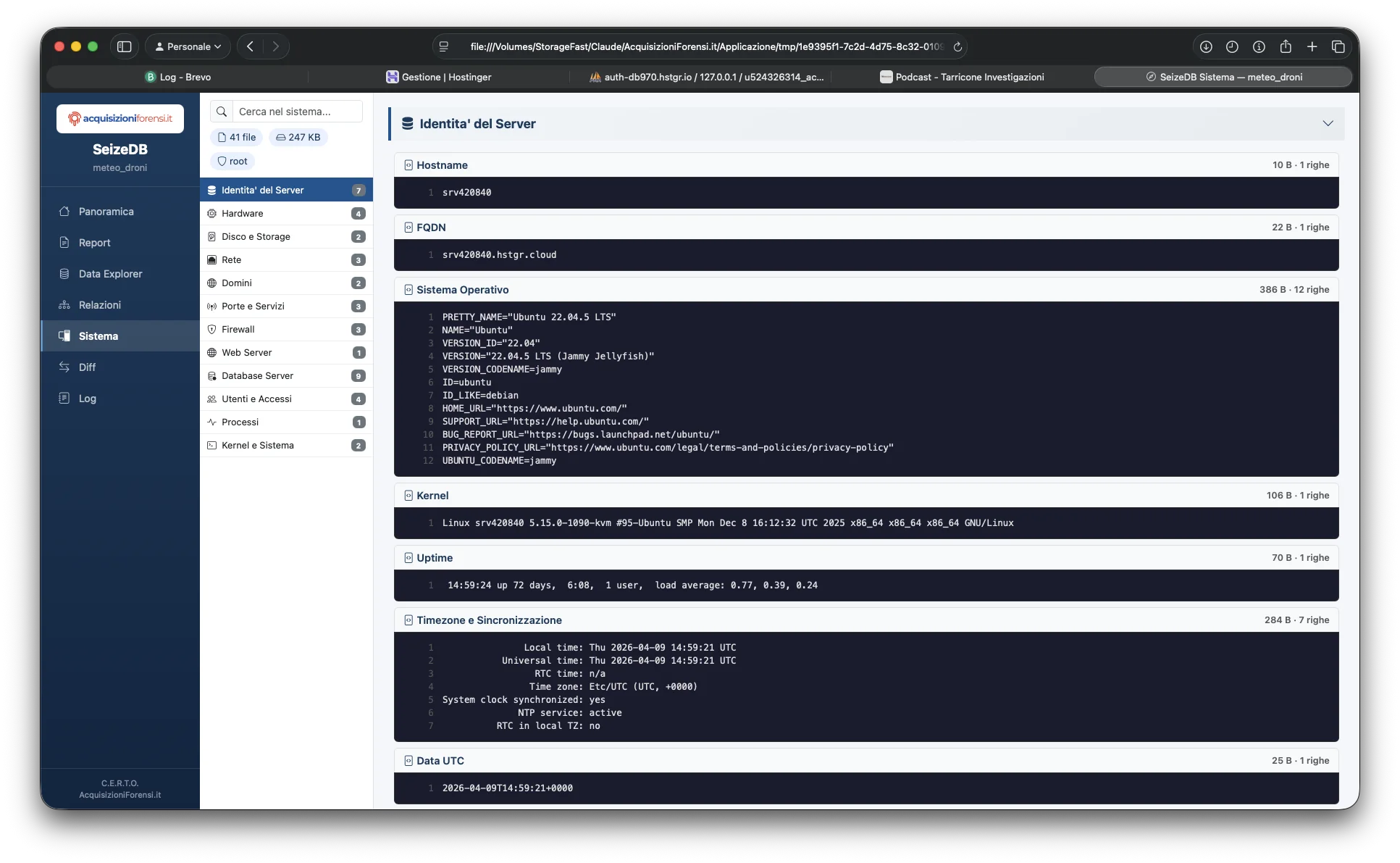
System Info
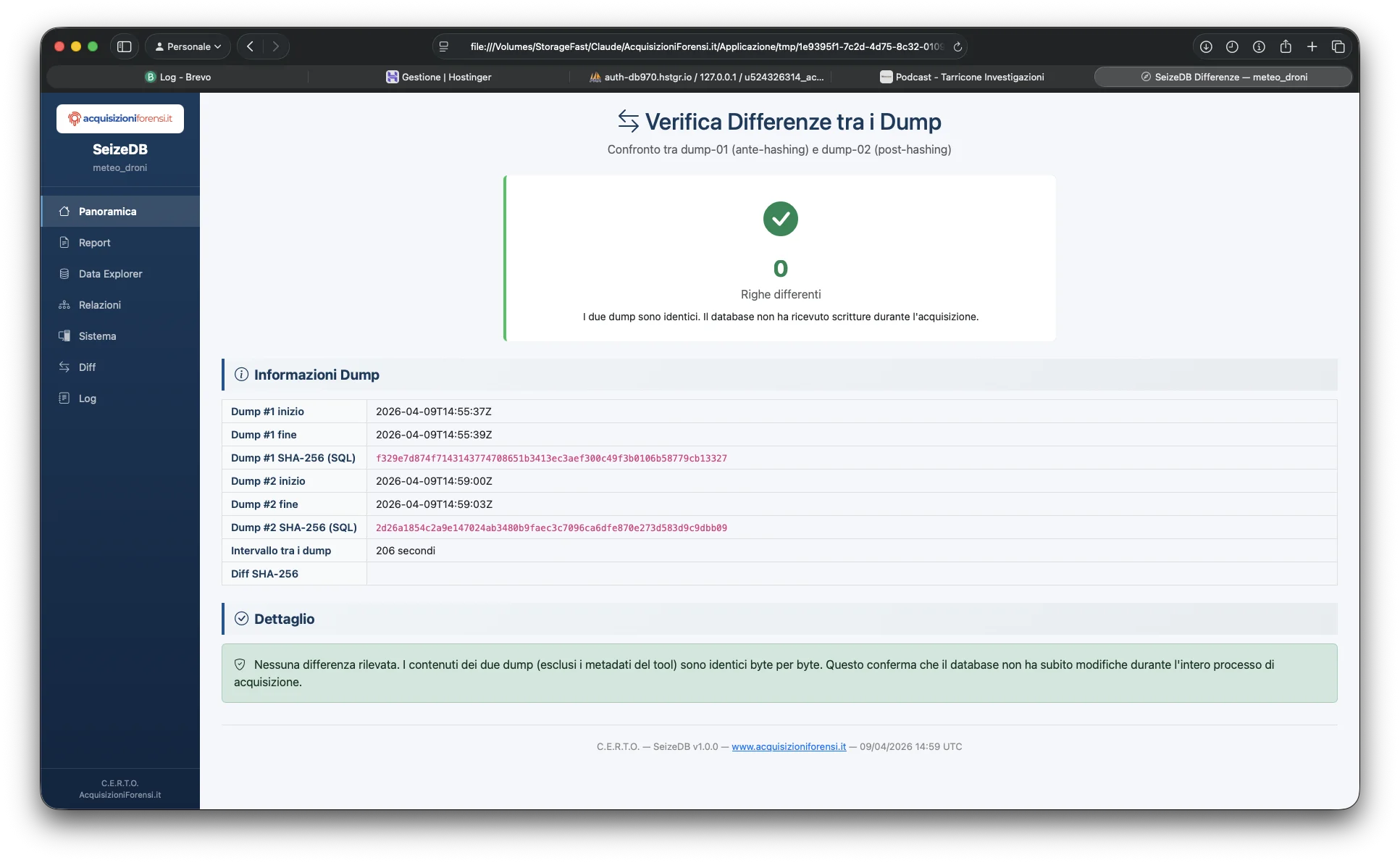
Verifica Differenze
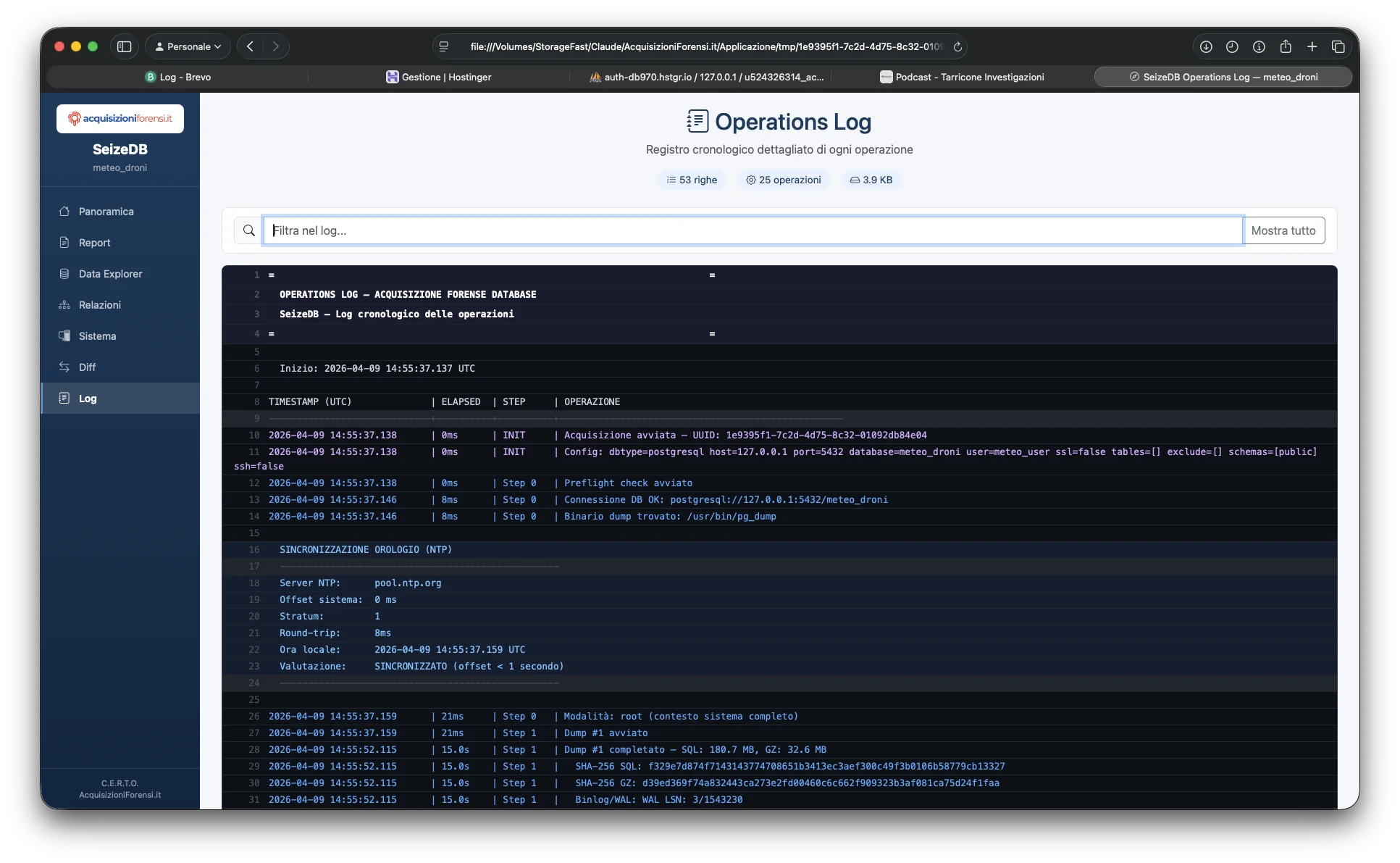
Operations Log
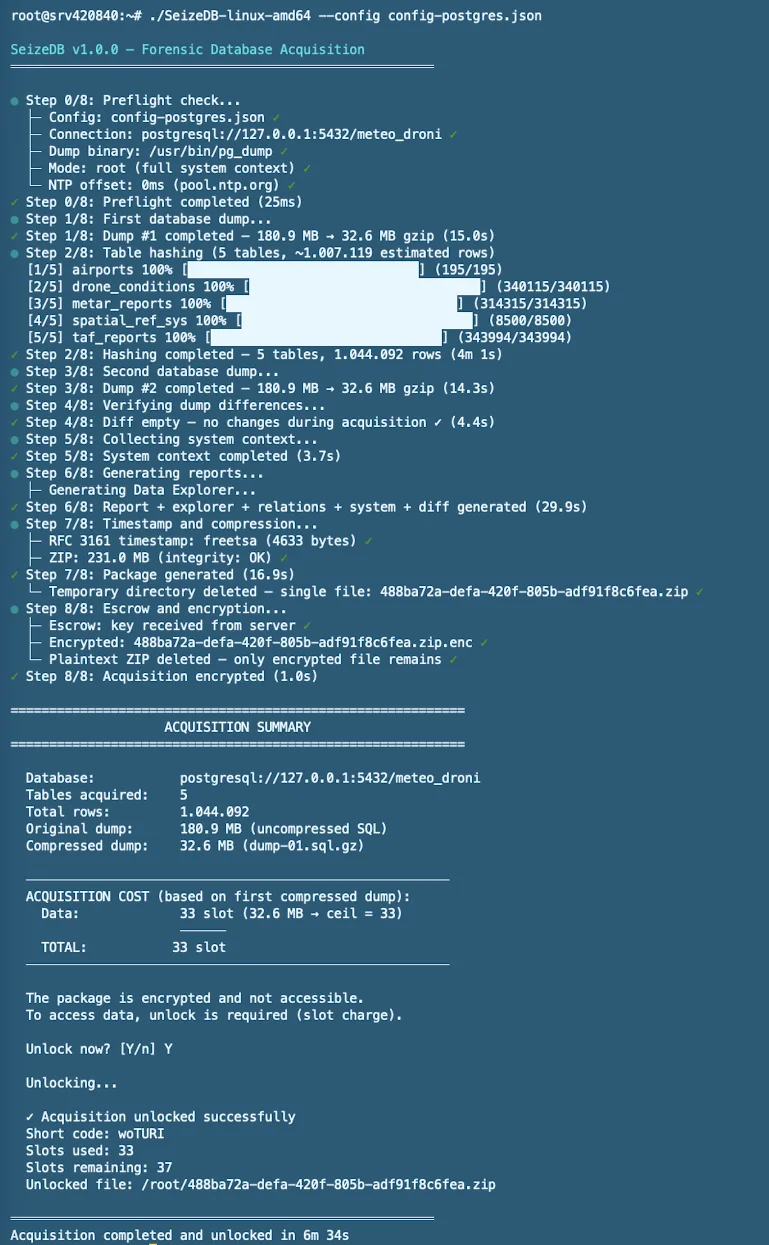
Console Output
Come verificare l'integrità dell'acquisizione
# Verificare l'hash di un dump
sha256sum dump/dump-01-*.sql.gz
# Confrontare con il valore in dump/dump-01.gz.sha256
# Verificare una singola riga
# Trovare la riga in tables/{tabella}/rows.jsonl
# Ricalcolare SHA-256 sui dati della riga (escludendo _row_hash, _pk, _table)
# Confrontare con il valore _row_hashPermessi database minimi
MySQL / MariaDB
CREATE USER 'forense_ro'@'%' IDENTIFIED BY 'password';
GRANT SELECT, SHOW VIEW, PROCESS, REPLICATION CLIENT ON *.* TO 'forense_ro'@'%';
FLUSH PRIVILEGES;PostgreSQL
CREATE ROLE forense_ro WITH LOGIN PASSWORD 'password';
GRANT CONNECT ON DATABASE nome_db TO forense_ro;
GRANT USAGE ON SCHEMA public TO forense_ro;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO forense_ro;
GRANT pg_monitor TO forense_ro;Riferimenti normativi
| ISO/IEC 27037:2012 | Identificazione, raccolta, acquisizione e preservazione di prove digitali |
| ISO/IEC 27042:2015 | Analisi e interpretazione delle prove digitali |
| RFC 3161 | Time-Stamp Protocol per la marca temporale forense |
| Art. 234 c.p.p. | Ammissibilità delle prove documentali informatiche |
| L. 48/2008 | Ratifica Convenzione di Budapest — informatica forense in Italia |
| D.Lgs. 82/2005 art. 20 | Validità ed efficacia probatoria dei documenti informatici |
| Regolamento eIDAS (UE 910/2014) art. 41-42 | Validazione temporale elettronica qualificata |
| GDPR (UE 2016/679) art. 9(2)(f) | Trattamento per accertamento in sede giudiziaria |