Perché uno screenshot di Telegram non basta
Uno screenshot di una chat Telegram non ha alcun valore probatorio autonomo. Chiunque può modificare il contenuto di una pagina web tramite Inspect Element del browser, editare l'HTML in tempo reale e catturare un'immagine di messaggi mai esistiti. Uno screenshot:
- Non contiene metadati — mancano message ID, timestamp Unix, sender ID, informazioni sul forwarding
- Non prova l'esistenza del messaggio — nessun collegamento con i dati del protocollo MTProto
- Non rileva messaggi cancellati — impossibile individuare gap negli ID sequenziali
- È banalmente falsificabile — con DevTools, editing HTML o applicazioni di fotoritocco
L'acquisizione forense con C.E.R.T.O. Desktop 3.1 opera in modo radicalmente diverso: accede ai mirror del worker MTProto (testo in chiaro già decifrato dal client), estrae il testo dal DOM, scarica i media, rileva i gap negli ID dei messaggi (messaggi potenzialmente cancellati), registra l'intera sessione su video, cifra con chiave in escrow e appone marca temporale RFC 3161.
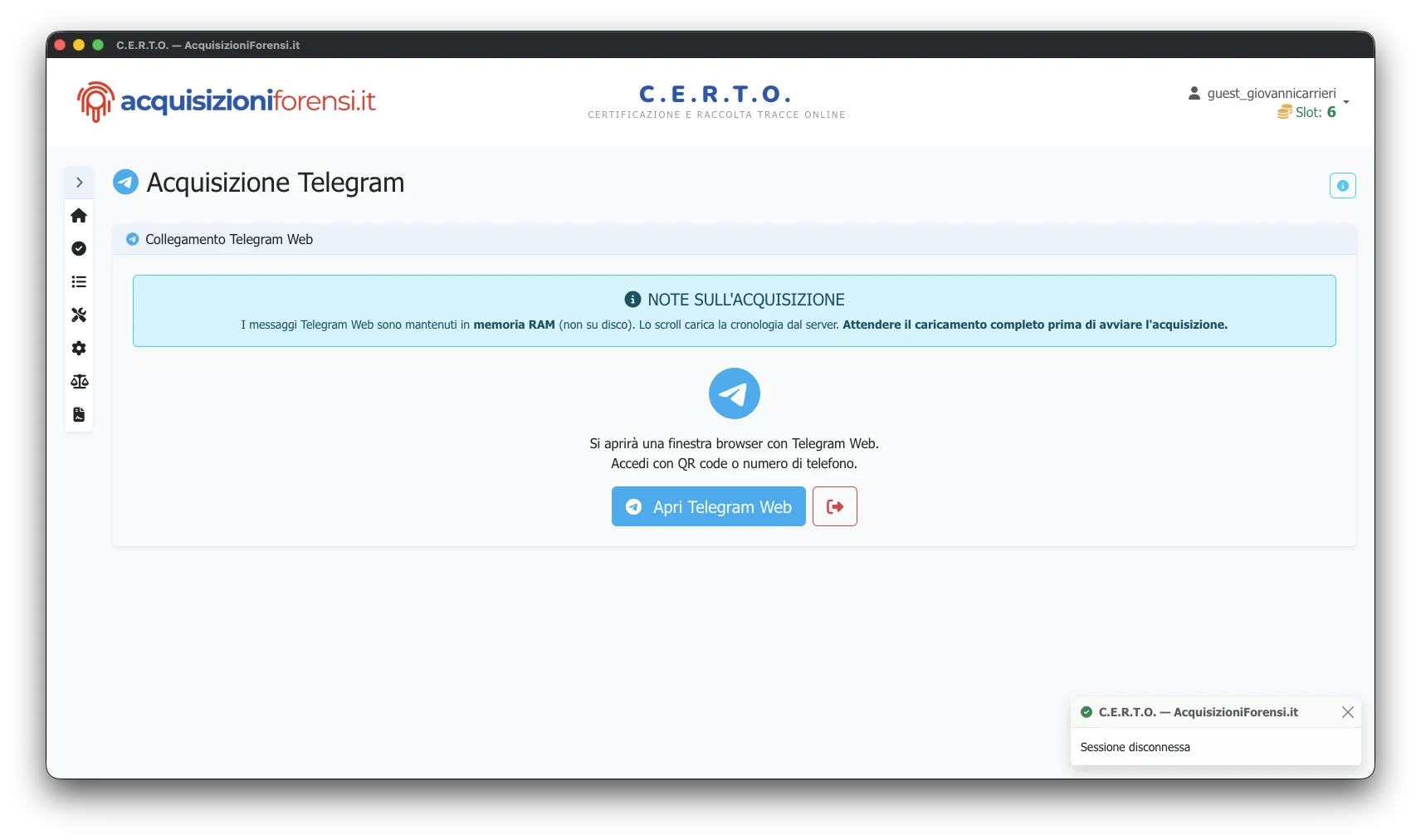
L'interfaccia di acquisizione Telegram
L'acquisizione si compone di tre fasi distinte, ciascuna con operazioni tecniche specifiche.
Accesso a Telegram Web
L'utente esegue il login a Telegram Web tramite QR code, scansionato dall'app Telegram sul proprio dispositivo mobile. C.E.R.T.O. rileva automaticamente l'avvenuto login mediante polling ogni 2 secondi sullo stato della sessione.
Al login completato, il sistema cattura automaticamente i dati di sessione:
- Auth key per Data Center — chiave di autenticazione in formato esadecimale per ciascun DC
- Server salt per DC — parametro crittografico della sessione MTProto
- userId, phone, username — estratti dai mirror del worker, IndexedDB e localStorage
- Contatti — salvati su disco per la persistenza della sessione
Sicurezza del trasporto: protocollo MTProto 2.0, cifratura AES-256-IGE, connessione WebSocket Secure (WSS). La sessione viene persistita in ~/.../Telegram-Acquisite/.telegram-session.json.
Selezione delle chat
L'elenco delle chat viene estratto tramite SCRIPT_GET_CHAT_LIST, uno script iniettato che valuta il DOM di Telegram Web. Per ciascuna chat vengono mostrati: nome, peerId, tipo e anteprima dell'ultimo messaggio.
Sono supportati tre tipi di chat:
| Tipo | Identificazione |
|---|---|
| Chat individuali (1:1) | peerId > 0 |
| Gruppi | peerId < 0, isGroup = true |
| Canali | peerId < 0, isChannel = true |
L'utente seleziona le chat da acquisire. Il sistema fornisce una stima delle dimensioni basata sul conteggio messaggi (scroll-up counting) e sull'analisi delle dimensioni dei media presenti nel testo (pattern kB/MB/GB).
Acquisizione, analisi e report
Per ciascuna chat selezionata, il sistema esegue una serie di operazioni automatizzate.
Caricamento cronologia — Scroll UP
Fino a 2.000 tentativi di scroll verso l'alto (incrementi di 700px) per caricare l'intera cronologia dei messaggi nel mirror MTProto. Il conteggio dei messaggi nel mirror viene verificato ogni 1.500ms. Lo scroll si arresta quando il sistema raggiunge la cima della chat per 10 volte consecutive oppure non rileva nuovi messaggi per 15 tentativi.
Estrazione testo — Scroll DOWN
Scroll dall'alto verso il basso, massimo 200 step, ciascuno pari al 90% del viewport. Durante ogni step vengono estratti tutti i messaggi visibili dal DOM: message ID (mid), testo, nome autore, timestamp e classi CSS.
Tripla estrazione dati
| Sorgente | Priorità | Dati estratti |
|---|---|---|
| Mirror JS | Primaria | port.mirrors.messages[peerId] — oggetti strutturati con id, date, fromId, message, media, out, views, replyToId, fwdFromId |
| DOM | Secondaria | Bubble dei messaggi visibili con testo, autore, timestamp (fallback) |
| Cache API | Terziaria | Foto profilo dallo store 'cachedFiles' del browser |
Download media
| Tipo media | Metodo di download |
|---|---|
| Foto | Blob URL dal DOM (naturalWidth > 200) → Media Viewer lightbox → Cache API → MTProto diretto |
| Video | Service Worker stream URL con richieste HTTP Range da 512KB, limite 100MB |
| Documenti | MTProto stream URL con inputDocumentFileLocation (dcId, documentId, accessHash, fileReference), chunk da 512KB |
| Audio / Vocali | Intercettazione download Electron (session.on('will-download')) |
| Foto profilo | Cache API con pattern photo_{photoId}_{sizeType} |
Gap detection
Per gruppi e canali (dove gli ID dei messaggi sono sequenziali per chat), il sistema analizza tutti gli ID tra il minimo e il massimo presenti, individuando gli ID mancanti. I gap vengono riportati come array missingIds nel file di metadati della chat.
Generazione HTML interattivo
Per ogni chat viene generato un file chat.html con bubble in stile Telegram, una palette di 10 colori assegnati via hash sul nome dell'autore, lightbox CSS-only per le foto, rendering inline di video/PDF/documenti, separatori per data e lazy loading delle immagini.
Post-elaborazione
Al termine dell'estrazione, il sistema esegue automaticamente:
- Sincronizzazione oraria NTP e rilevamento IP pubblico
- Snapshot dei processi di sistema (
ps aux) - Generazione report in formato TXT e PDF
- Calcolo hash manifest (MD5, SHA-1, SHA-256, SHA-512 per ogni file)
- Generazione registri per tipologia di file
- Cifratura escrow AES-256-CBC (chiave lato server)
- Marca temporale RFC 3161 (FreeTSA o InfoCert eIDAS)
- Creazione archivio ZIP finale
Esempio reale: acquisizione di un gruppo Telegram
| Chat | Gruppo Test Forense (gruppo, 5 partecipanti) |
| Messaggi estratti | 1.247 |
| Media scaricati | 89 (52 foto, 19 video, 12 documenti, 6 audio) |
| Dimensione media | 312,5 MB |
| Gap detection | 23 message ID mancanti su range 1–1.270 |
| ID acquisizione | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx |
I file generati dall'acquisizione
Al termine dell'acquisizione, C.E.R.T.O. genera una struttura completa di file organizzati per categoria.
Rapporto e log
| File | Descrizione |
|---|---|
rapporto-acquisizione.pdf |
Report completo dell'acquisizione in formato PDF con intestazione, dettagli sessione, elenco chat, hash e metadati |
rapporto-acquisizione.txt |
Versione testuale del report, leggibile senza software dedicato |
rapporto-acquisizione.tsr |
Timestamp Response RFC 3161 applicata al report PDF |
acquisizione-log.txt |
Log dettagliato di tutte le operazioni eseguite durante l'acquisizione |
rapporto-processi-sistema.txt |
Snapshot dei processi attivi sul sistema al momento dell'acquisizione (ps aux) |
Rete
| File | Descrizione |
|---|---|
network-capture.har |
Cattura completa del traffico HTTP e WebSocket in formato HAR (HTTP Archive) |
network-capture-global.json |
Eventi CDP (Chrome DevTools Protocol) aggregati per l'intera sessione |
Video sessione (screenshot-recorded/)
| File | Descrizione |
|---|---|
frame_NNNNN_Nms.jpg |
Frame singoli catturati a 1 FPS durante l'intera sessione di acquisizione |
session-recording.webm |
Video completo della sessione generato con FFmpeg dai frame catturati |
recording-info.json |
Metadati della registrazione: durata, numero frame, risoluzione, timestamps |
Dati sessione (json/)
| File | Descrizione |
|---|---|
auth-session-data.json |
Chiavi di autenticazione per Data Center e server salt della sessione MTProto |
users-map.json |
Mappa userId → firstName, lastName, username, phone, isBot |
chat-list.json |
Elenco completo delle chat dell'account al momento dell'acquisizione |
telegram-session-info.json |
Informazioni sessione: userId, dcId, nome database IndexedDB |
local-storage.json |
Dump completo del localStorage del browser per Telegram Web |
session-storage.json |
Dump completo del sessionStorage del browser |
indexeddb-tweb-account-*.json |
Dump degli store IndexedDB dell'account Telegram Web (dati applicativi) |
Dati per chat (chat/[NomeChat]/)
| File | Descrizione |
|---|---|
mirror-messages.json |
Oggetti raw dal mirror MTProto: struttura completa con id, date, fromId, message, media, views, reply, forward |
messages.json |
Messaggi estratti dal DOM durante la fase di scroll down |
messages-readable.txt |
Trascrizione leggibile della chat in formato testo, con autore, data e contenuto |
chat.html |
Visualizzatore interattivo con bubble stile Telegram, lightbox per foto, player video e documenti inline |
metadata.json |
Conteggi messaggi/media, metodo di estrazione utilizzato, array missingIds per gap detection |
Media per chat (chat/[NomeChat]/media/)
| File | Descrizione |
|---|---|
photo_{mid}.jpg |
Foto scaricate, nominate con il message ID del messaggio di appartenenza |
video_{mid}.mp4 |
Video scaricati tramite range request dal Service Worker |
doc_{mid}.bin |
Documenti scaricati via stream MTProto con estensione originale preservata nel metadata |
profile-photos/ |
Sottocartella con le foto profilo dei partecipanti, estratte dalla Cache API |
Registri hash (registri/)
| File | Descrizione |
|---|---|
registro-immagini.txt |
Hash MD5, SHA-1, SHA-256, SHA-512 per ogni file immagine acquisito |
registro-video.txt |
Hash MD5, SHA-1, SHA-256, SHA-512 per ogni file video acquisito |
registro-files.txt |
Hash MD5, SHA-1, SHA-256, SHA-512 per ogni documento acquisito |
registro-json.txt |
Hash MD5, SHA-1, SHA-256, SHA-512 per ogni file JSON generato |
registro-screenshot.txt |
Hash MD5, SHA-1, SHA-256, SHA-512 per ogni frame della registrazione video |
Manifest e integrità
| File | Descrizione |
|---|---|
file-manifest.json |
Elenco completo di tutti i file generati con percorso, dimensione e data di creazione |
{id}-hashes.json |
Hash consolidati (MD5, SHA-1, SHA-256, SHA-512) per ogni file dell'acquisizione |
verifica-integrita.sh |
Script Bash per la verifica automatica dell'integrità dei file su macOS/Linux |
verifica-integrita.bat |
Script Batch per la verifica automatica dell'integrità dei file su Windows |
Marca temporale
| File | Descrizione |
|---|---|
freetsa-cacert/freetsa-cacert.pem |
Certificato CA della TSA (Time Stamping Authority) per la verifica della marca temporale |
freetsa-cacert/tsr-verifica.txt |
Istruzioni e comandi OpenSSL per la verifica indipendente della marca temporale |
timestamp-info.json |
Metadati della marca temporale: TSA utilizzata, hash del file marcato, data e ora UTC |
Cosa rende completa un'acquisizione Telegram
| Elemento | Descrizione tecnica |
|---|---|
| Tripla estrazione | Mirror JS (primaria) + DOM (secondaria) + Cache API (terziaria), unificati per message ID. Il mirror fornisce i dati strutturati, il DOM il fallback testuale, la Cache API i media in cache. |
| Gap detection ID messaggi | Analisi sequenziale degli ID per gruppi e canali. Individua tutti gli ID mancanti tra il minimo e il massimo presenti, generando l'array missingIds. Evidenzia potenziali cancellazioni. |
| Download media multi-metodo | Foto: blob URL → Media Viewer → Cache API → MTProto diretto. Video e documenti: range request da 512KB via Service Worker. Audio: intercettazione Electron (will-download). |
| HTML interattivo con lightbox | Lightbox CSS-only per le foto, palette di 10 colori assegnati via hash sull'autore, rendering inline di video/PDF, separatori per data, overlay con metadati. |
| Risoluzione UsersMap | Mapping userId → nome, telefono, username dal mirror MTProto. Fallback: ricostruzione da IndexedDB per utenti non presenti nel mirror. |
| Registrazione video | Cattura a 1 FPS in formato JPEG + assemblaggio WebM con FFmpeg. Documenta l'intera sessione dalla scansione del QR code al completamento. |
| Intercettazione rete CDP | Cattura in formato HAR di tutte le richieste HTTP, frame WebSocket e risposte CDN per ciascuna chat acquisita. |
| Escrow encryption + RFC 3161 | Cifratura AES-256-CBC con chiave custodita lato server. Marca temporale FreeTSA o InfoCert eIDAS conforme allo standard RFC 3161. |
Domande frequenti
Acquisisci le chat Telegram con valore legale
Tripla estrazione, gap detection, marca temporale RFC 3161 e cifratura escrow in un unico flusso automatizzato.
Registrati gratis Vedi i prezzi