Il modulo Telegram di C.E.R.T.O. Desktop acquisisce conversazioni da Telegram Web con piena validità forense. L'estrazione avviene tramite una tecnica a tripla sorgente: Mirror JS (messaggi decifrati dal worker MTProto), DOM (testo visibile nel browser) e Cache API (media e foto profilo). I media vengono scaricati con range request a blocchi da 512 KB. Per gruppi e canali, il sistema rileva automaticamente i gap nei message ID, segnalando potenziali messaggi eliminati. Il fascicolo include una chat HTML navigabile con lightbox, video recording della sessione, cifratura escrow AES-256 e marca temporale RFC 3161.
Costo: 1 slot per chat acquisita — vedi pacchetti slot
Come funziona l'acquisizione Telegram
L'acquisizione si basa su Telegram Web: l'utente effettua il login tramite QR code scansionato con il proprio smartphone e C.E.R.T.O. accede alla sessione in modalità esclusivamente di lettura. Il sistema utilizza il Chrome DevTools Protocol per intercettare il traffico di rete e accede direttamente al worker MTProto del browser per ottenere i messaggi già decifrati, senza necessità di gestire le chiavi di cifratura.
Il modulo è progettato per acquisizioni in ambito giudiziario: contenziosi civili, procedimenti penali, indagini difensive e CTU che coinvolgono conversazioni Telegram, gruppi o canali.
Trasporto cifrato: Telegram utilizza il protocollo MTProto 2.0 con cifratura AES-256-IGE su WebSocket Secure (WSS). C.E.R.T.O. non intercetta il traffico cifrato, ma accede ai messaggi dopo la decifratura nel browser, attraverso i mirror interni del worker MTProto (port.mirrors.messages). I dati acquisiti sono in chiaro perché già decifrati dal client Telegram Web.
Cosa acquisisce il modulo Telegram
Per ogni chat selezionata, il modulo produce un fascicolo forense completo contenente messaggi, media, rendering HTML interattivo, intercettazione di rete e dati di sessione.
| Elemento acquisito | Dettagli |
|---|---|
| Messaggi (tripla sorgente) | Estrazione da Mirror JS (worker MTProto, dati strutturati e decifrati), DOM (testo visibile, autore, timestamp) e Cache API (media in cache del browser). Mirror JS ha priorità, DOM è il fallback per il testo. |
| Media scaricati | Foto (blob URL o Media Viewer o Cache API), video (stream URL con range request 512 KB, limite 100 MB), documenti (stream MTProto), messaggi vocali/audio (intercettazione download Electron). |
| Chat HTML con lightbox | File HTML autocontenuto con stile Telegram: bolle messaggi, media inline (foto, video, PDF embed), lightbox CSS-only per le immagini, colori autore hash-based (10 colori), separatori data, lazy loading. |
| Gap detection message ID | Per gruppi e canali: analisi della sequenza dei message ID per rilevare ID mancanti (potenziali messaggi eliminati, rimossi da admin o auto-cancellati). Non applicabile alle chat 1:1 (ID globali). |
| Video recording sessione | Cattura continua a 1 FPS della sessione Telegram Web in formato JPEG, convertita in video WebM con FFmpeg. |
| Intercettazione rete | HAR completo delle richieste HTTP e log degli eventi CDP (Chrome DevTools Protocol). Cattura WebSocket frame per chat. |
| Dati di sessione | Auth key per Data Center, server salt, userId, phone, username, cookie, localStorage e sessionStorage completi. Dump IndexedDB di tutti i database di Telegram Web. |
| Mappa utenti | Dizionario userId → nome, cognome, username, telefono, flag bot. Estratto dal mirror MTProto con fallback a ricostruzione da IndexedDB. |
| Hash crittografici (x4) | MD5, SHA-1, SHA-256 e SHA-512 per ogni file del fascicolo. Registri separati per tipo (immagini, video, documenti, JSON, screenshot). |
| Contesto di sistema | Sincronizzazione NTP (offset documentato), IP pubblico del client, snapshot dei processi in esecuzione (ps aux / tasklist). |
| Report forense | Documento TXT e PDF con account, interlocutori, lista chat, riepilogo, gap detection, inventario hash e catena di custodia. |
| Cifratura escrow + timestamp | Fascicolo cifrato con AES-256-CBC escrow (chiave custodita dal server). Marca temporale RFC 3161 (FreeTSA o InfoCert eIDAS). |
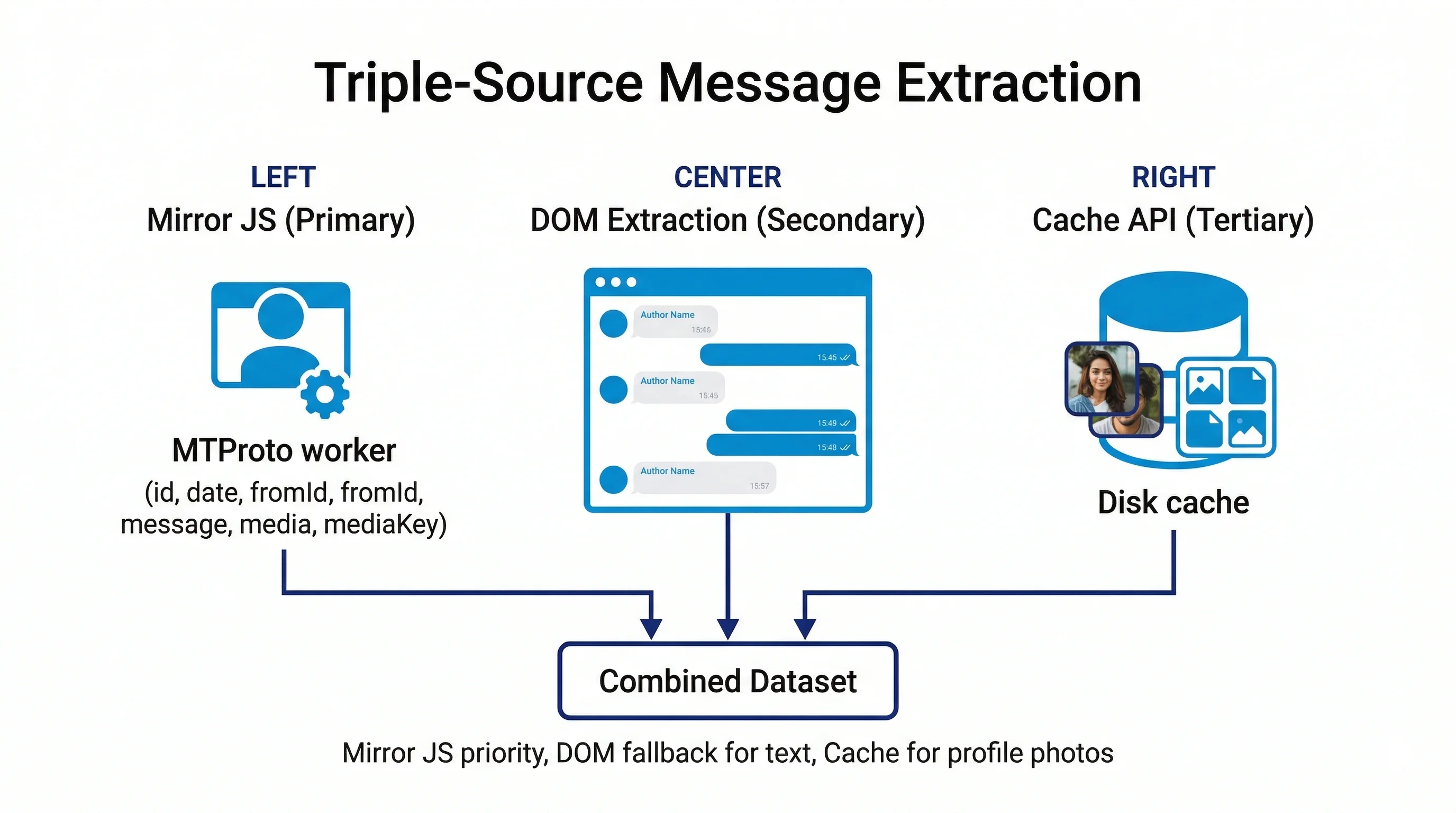
Estrazione messaggi: Mirror JS, DOM e Cache API
Il modulo utilizza una strategia di estrazione a tripla sorgente con priorità definita, per massimizzare la completezza e offrire ridondanza forense.
Mirror JS (primaria)
Accesso diretto al worker MTProto del browser tramite port.mirrors.messages[peerId]. I messaggi sono già decifrati e disponibili come oggetti JavaScript strutturati.
- Campi: id, date, fromId, message, media, out, views, replyToId, fwdFromId
- Sorgente più completa e affidabile
- Include metadati media (mediaKey, size, mimeType)
DOM (secondaria)
Estrazione del testo visibile dalle bolle messaggi nel DOM di Telegram Web durante lo scroll progressivo della chat.
- Campi: mid, text, authorName, timestamp, classes
- Fallback per il testo quando il mirror è vuoto
- Utile per nomi autore e formattazione visibile
Cache API (terziaria)
Estrazione di media e foto profilo dalla cache del browser (caches.open('cachedFiles')).
- Foto profilo dei partecipanti
- Foto di album non visibili nella griglia media
- Fallback con download MTProto diretto
L'acquisizione della cronologia messaggi avviene in due fasi di scroll: scroll UP (fino a 2000 tentativi, per caricare la cronologia completa nel mirror MTProto) e scroll DOWN (per estrarre il testo DOM visibile). Il conteggio messaggi viene monitorato in tempo reale fino alla stabilizzazione.
Download media: foto, video e documenti
Il download dei media utilizza metodi diversi per tipo di contenuto, adattandosi all'architettura di Telegram Web che serve i file tramite Service Worker con range request.
| Tipo media | Metodo di download | Formato output |
|---|---|---|
| Foto | Blob URL dal DOM (full-size, naturalWidth > 200px) → fallback Media Viewer (lightbox) → fallback Cache API → fallback download MTProto diretto | photo_{mid}.jpg|png|webp |
| Video | Stream URL dal Service Worker con range request a blocchi da 512 KB. Dimensione estratta dai parametri JSON dell'URL. Limite: 100 MB per video | video_{mid}.mp4|webm|mov |
| Documenti | Stream URL MTProto con parametri inputDocumentFileLocation (dcId, documentId, accessHash, fileReference). Range request 512 KB | doc_{mid}.bin o nome originale |
| Audio / vocali | Intercettazione download Electron (session.on('will-download')). Fallback a stream URL | Formato originale (ogg, mp3, m4a) |
| Foto profilo | Cache API del browser (cachedFiles), ricerca per pattern photo_{photoId}_{sizeType} | profile_{peerId}_{photoId}.jpg |
Per gruppi e canali, il download utilizza la griglia media del pannello laterale: il sistema apre il pannello destro, clicca sulla tab Media, scorre la griglia per caricare tutti gli elementi, poi apre ciascun media nel viewer per scaricare la versione full-size.
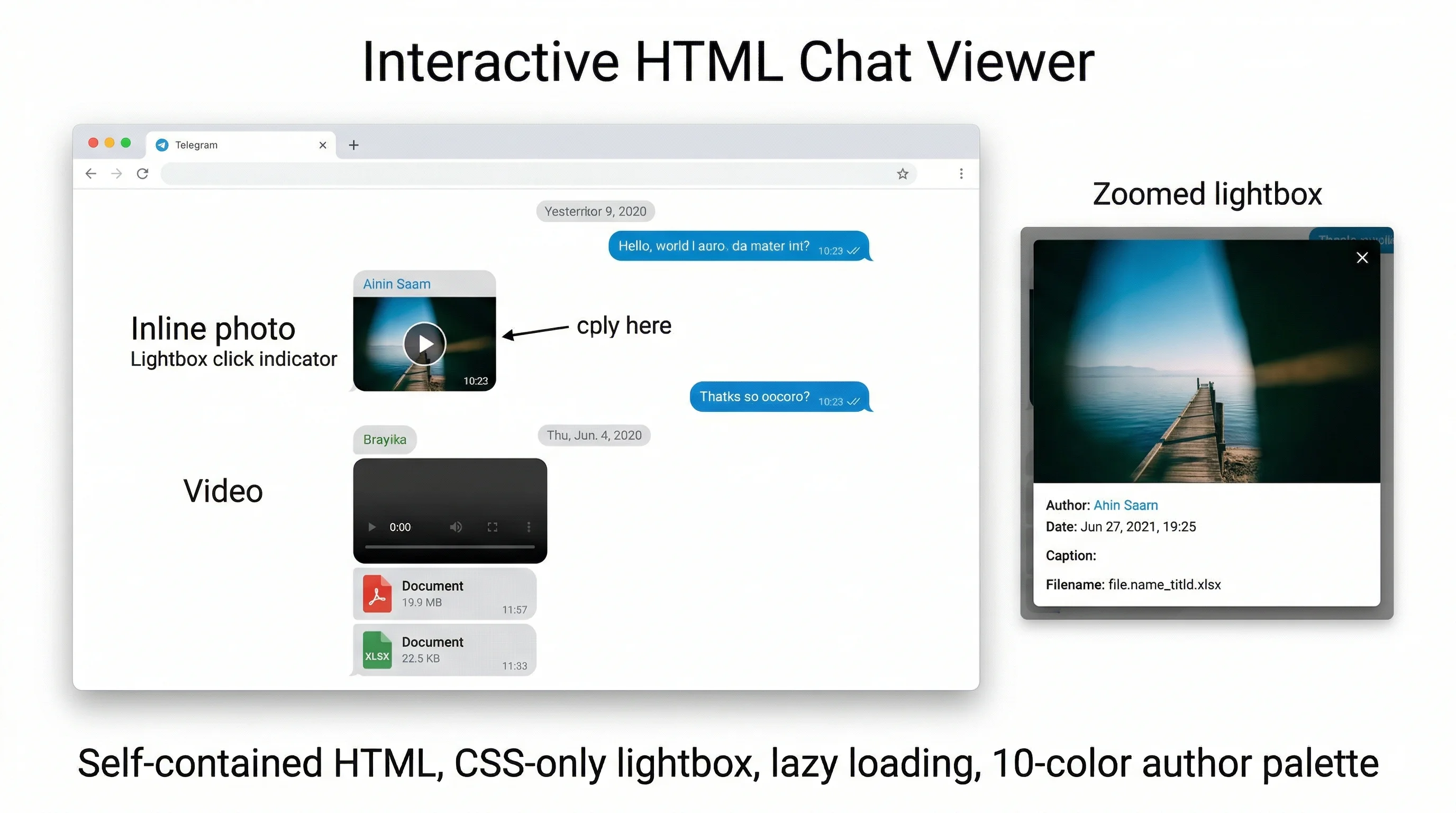
Chat HTML navigabile con lightbox
Per ogni chat acquisita, il sistema genera un file HTML autocontenuto che riproduce la conversazione con uno stile simile a Telegram Web. Il file è navigabile offline, senza dipendenze esterne.
Layout della chat
- Bolle messaggi: blu (in uscita), grigio (in entrata)
- 10 colori autore determinati da hash (consistenti in tutta la chat)
- Timestamp HH:MM per ogni messaggio
- Separatori di data (DD/MM/YYYY) tra giorni diversi
- URL convertiti in link cliccabili
- Design responsive (mobile-friendly)
Media inline e lightbox
- Foto: thumbnail inline con click → lightbox CSS-only a schermo intero
- Video: player HTML5 con controlli nativi e preload metadata
- PDF: embed inline nel messaggio
- Documenti: icona colorata per estensione (PDF rosso, Excel verde, Word blu, ZIP arancione) + link download
- Lightbox: overlay con metadati (autore, data, ora, caption, filename) e pulsante chiudi
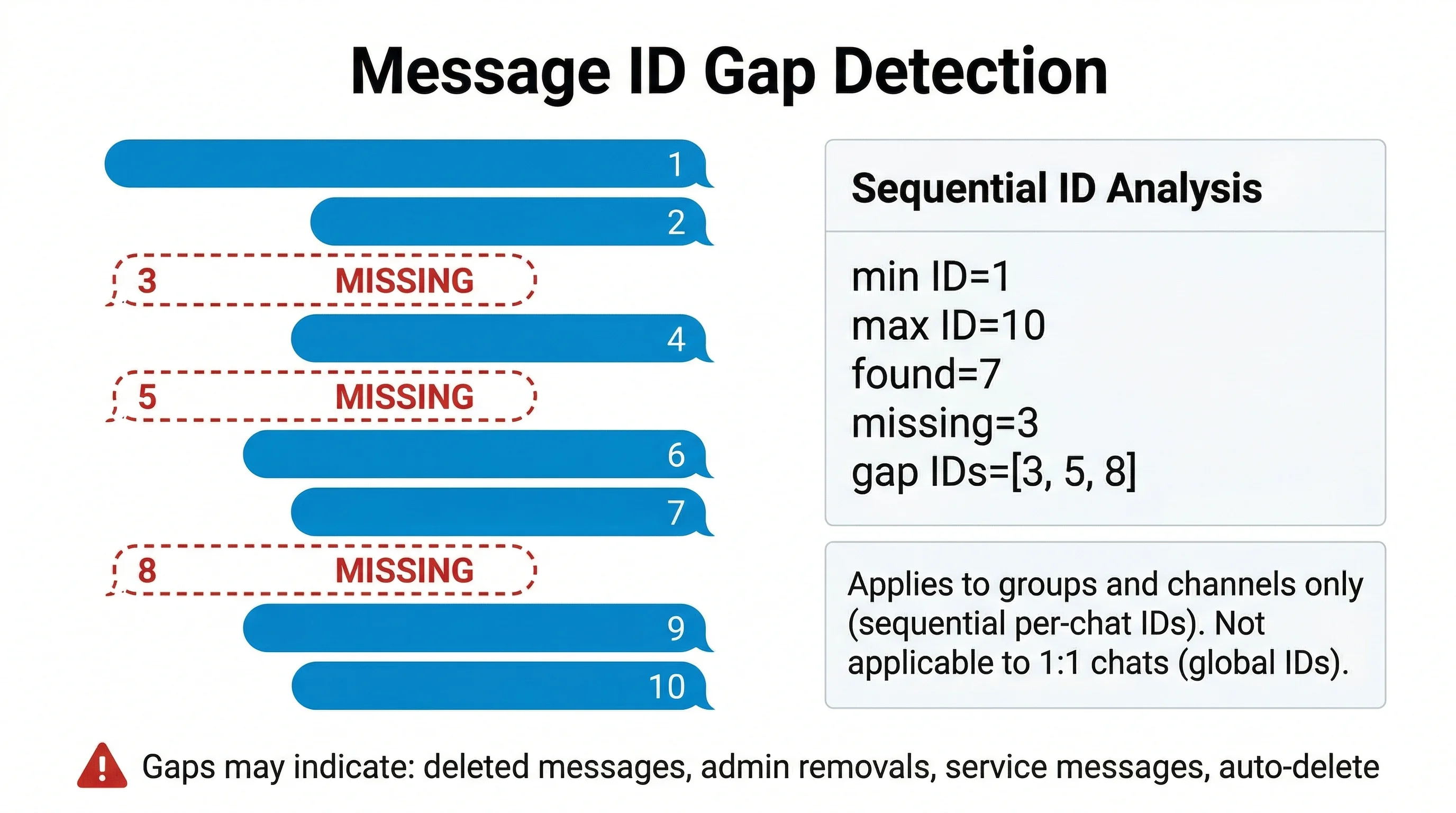
Rilevamento messaggi eliminati (gap detection)
Nei gruppi e canali Telegram, i message ID sono sequenziali all'interno della chat. Il sistema analizza la sequenza di ID acquisiti e segnala ogni ID mancante tra il minimo e il massimo rilevato.
Come funziona
- Si estraggono tutti i message ID dalla chat acquisita
- Si calcola la sequenza attesa dal minimo al massimo ID
- Ogni ID presente nella sequenza attesa ma assente nei messaggi acquisiti viene marcato come mancante
- I gap vengono salvati in
metadata.jsoncome arraymissingIdse riportati nel report forense
Possibili cause di un gap
- Messaggio eliminato dall'autore
- Messaggio rimosso da un amministratore
- Messaggio di servizio (aggiunta/rimozione membro, cambio titolo)
- Messaggio con auto-cancellazione scaduto
- Messaggio programmato mai pubblicato
Limitazione: la gap detection si applica solo a gruppi e canali, dove i message ID sono sequenziali per chat. Nelle chat individuali (1:1) gli ID sono globali sull'intero account, quindi la presenza di gap è normale e non indica messaggi eliminati.
Dati di sessione e mappa utenti
Il modulo acquisisce i dati tecnici della sessione Telegram Web che documentano l'identità dell'account, lo stato dell'autenticazione MTProto e la mappa completa degli utenti conosciuti.
Autenticazione MTProto
- Auth key per ogni Data Center (hex)
- Server salt per DC (hex)
- User ID numerico
- Numero di telefono
- Username (@handle)
- Data Center di appartenenza
Mappa utenti (UsersMap)
- Dizionario userId → profilo completo
- Nome, cognome, username, telefono
- Flag bot
- Sorgente: mirror MTProto (primaria) o ricostruzione da IndexedDB (fallback)
- Usata per risolvere i nomi nella chat HTML
Storage del browser
- Cookie completi
- localStorage (dump completo)
- sessionStorage (dump completo)
- IndexedDB: dump di tutti i database di Telegram Web (account, stores, sample)
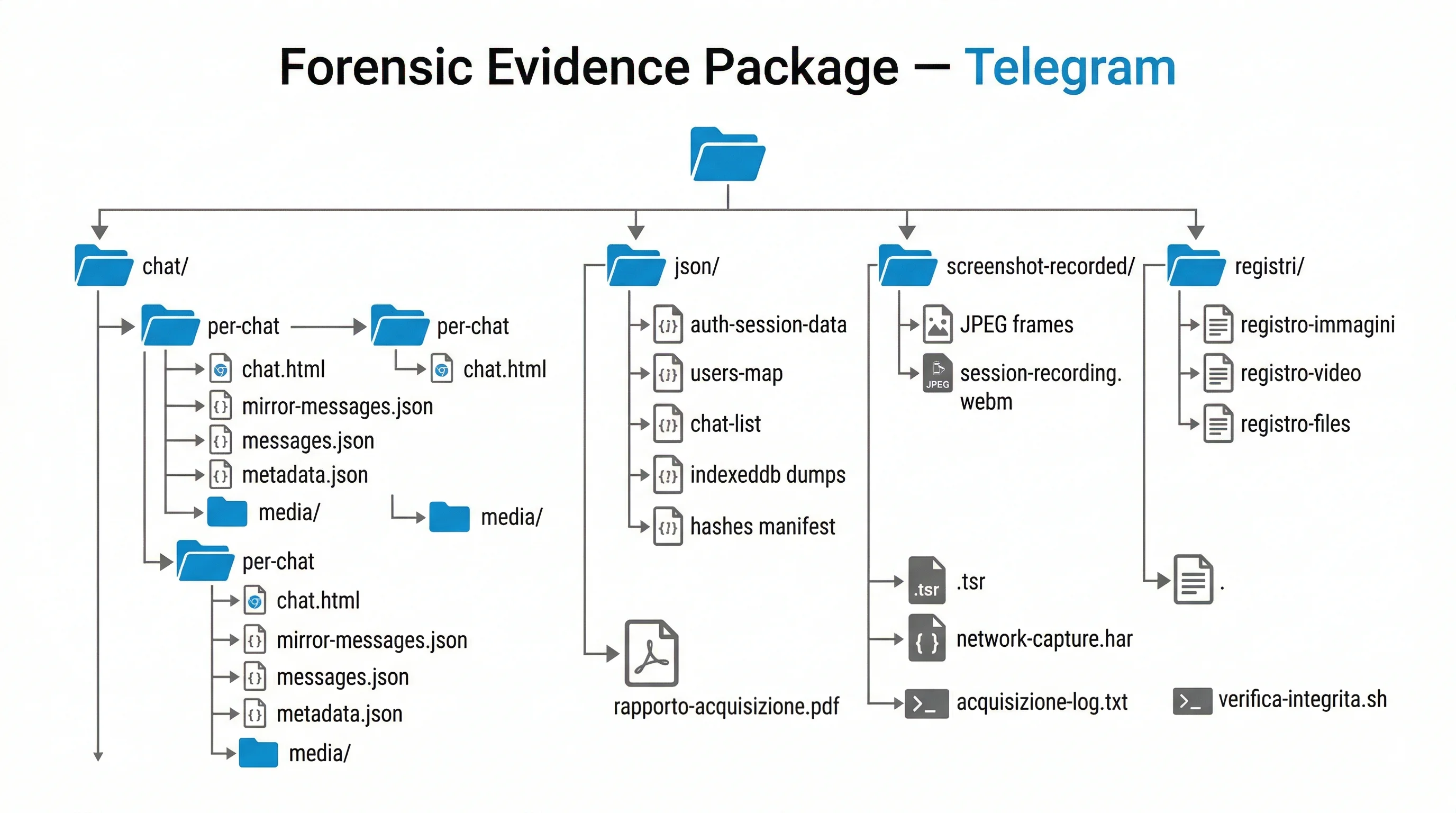
Il fascicolo forense prodotto
Ogni acquisizione genera un archivio cifrato contenente tutti gli artefatti forensi, organizzati per chat e per tipo.
├── chat/
│ └── [NomeChat]/ — directory per ogni chat acquisita
│ ├── mirror-messages.json — messaggi dal mirror MTProto
│ ├── messages.json — estrazione DOM
│ ├── messages-readable.txt — trascrizione leggibile
│ ├── chat.html — rendering HTML con lightbox
│ ├── metadata.json — conteggi, gap detection, metodo
│ └── media/
│ ├── photo_{mid}.jpg — foto scaricate
│ ├── video_{mid}.mp4 — video (max 100 MB)
│ ├── doc_{mid}.bin — documenti
│ └── profile-photos/ — foto profilo partecipanti
├── json/
│ ├── auth-session-data.json — auth key e server salt per DC
│ ├── users-map.json — dizionario userId → profilo
│ ├── chat-list.json — lista completa chat dell'account
│ ├── telegram-session-info.json — metadati sessione
│ ├── local-storage.json — dump localStorage
│ ├── session-storage.json — dump sessionStorage
│ ├── indexeddb-tweb-*.json — dump database IndexedDB
│ ├── file-manifest.json — inventario file con dimensioni
│ ├── {id}-hashes.json — manifest SHA-256 globale
│ └── timestamp-info.json — metadati marca temporale
├── screenshot-recorded/
│ ├── frame_00000_0ms.jpg ... — frame catturati a 1 FPS
│ ├── recording-info.json — metadati registrazione
│ └── session-recording.webm — video della sessione
├── registri/ — hash separati per tipo
│ ├── registro-immagini.txt
│ ├── registro-video.txt
│ ├── registro-files.txt
│ ├── registro-json.txt
│ └── registro-screenshot.txt
├── freetsa-cacert/
│ ├── freetsa-cacert.pem — CA per verifica offline
│ └── tsr-verifica.txt — comando OpenSSL
├── rapporto-acquisizione.txt — report forense
├── rapporto-acquisizione.pdf — report PDF
├── rapporto-acquisizione.tsr — marca temporale RFC 3161
├── network-capture.har — log HTTP/WebSocket in formato HAR
├── rapporto-processi-sistema.txt — snapshot processi attivi
├── acquisizione-log.txt — log cronologico
├── verifica-integrita.sh — script verifica macOS/Linux
└── verifica-integrita.bat — script verifica Windows
Contenuto del report forense
Il documento rapporto-acquisizione.pdf include:
- Account Telegram: nome, telefono, username, user ID, Data Center
- Metodo di autenticazione (QR code) e modalità di accesso (read-only)
- Tecnica di estrazione: Mirror JS + DOM + Cache API + Media Viewer
- Sicurezza trasporto: MTProto 2.0, AES-256-IGE, WSS
- Sincronizzazione NTP con offset documentato e IP pubblico
- Dati di autenticazione: auth key per DC, server salt, conteggio chiavi
- Elenco interlocutori con numeri di telefono, username e user ID
- Lista completa delle chat visibili (prime 50 con tipo: canale/gruppo/chat)
- Riepilogo: chat acquisite, messaggi totali, media scaricati/trovati, dimensione
- Dettaglio per chat: tipo, peer ID, messaggi, media, message ID mancanti
- Registri hash per tipo con MD5, SHA-1, SHA-256, SHA-512
- Hash dei file di sistema e hash dei registri stessi
Integrità, cifratura escrow e marca temporale
Come per il modulo WhatsApp, il fascicolo Telegram è protetto dalla cifratura escrow AES-256-CBC con chiave custodita dal server.
Hash per file (x4)
MD5, SHA-1, SHA-256, SHA-512 per ogni file del fascicolo. Registri separati per tipo (immagini, video, documenti, JSON, screenshot).
Cifratura escrow
ZIP e TAR cifrati con AES-256-CBC. Chiave e IV forniti dal server al momento dello sblocco. I file in chiaro vengono eliminati dopo la cifratura.
Marca temporale
RFC 3161 su rapporto-acquisizione.txt, applicata dopo la finalizzazione di tutti gli hash. FreeTSA (base) o InfoCert eIDAS (qualificata).
Script di verifica
verifica-integrita.sh (bash) e .bat (Windows) per ricalcolare SHA-256 di tutti i file e verificare la marca temporale con OpenSSL.
Resilienza: l'acquisizione è progettata per gestire errori a livello di singola chat o singolo media senza interrompere l'intero processo. Se una chat fallisce, il sistema registra l'errore e prosegue con la successiva. Il supporto per pausa e cancellazione consente di sospendere e riprendere l'acquisizione in qualsiasi momento. Lo stato finale è COMPLETATA (nessun errore), PARZIALE (alcuni errori) o FALLITA.
Acquisisci chat Telegram con valore forense
Scarica C.E.R.T.O. Desktop, effettua il login via QR code e ottieni un fascicolo forense completo delle conversazioni. 1 slot per chat.